2018年上半年NMT研究产出风起云涌
2017年被认为是神经机器翻译(NMT)变得主流的一年,但这并不意味着“问题被解决”,而且远非如此的是,任何使用这种高级在线机器翻译网站且精通双语的人都可以证明这一点。
而且,没有成千上万也有成百上千的研究人员在研究该问题。到2018年中,神经机器翻译(NMT)研究与去年同期相比骤增了115%。 2017年1月至6月,Slator在康奈尔大学的自动化在线研究分发系统Arxiv.org上发现了91篇与神经机器翻译(NMT)相关的研究论文(标题或摘要带关键词“神经机器翻译”)。 在今年同一时期,这一数字飙升至196。
正如我们之前所提醒的,有一些误报和神经机器翻译(NMT)作为一个活跃领域被提及或被用作测试与更大领域相关假设的实验,如自然语言处理(NLP)甚至机器学习和一般的深度学习。
还有重新提交的问题,即之前发布的研究论文的第一版更新了新信息或者做了更正。 虽然这些论文本身并非独一无二,但仍然会为在该领域开展的研究活动计数。
轻微降温
2018年可谓是一个疯狂的春天,世界上的一些大型科技公司发表了数十篇论文后,7月份的(论文)提交活动与前几个月相比竟然有所放缓。
7月份仅有26篇研究论文提交,其中只有9篇与神经机器翻译(NMT)直接相关,且并非之前提交的更新版本。
越来越多的研究论文会将神经机器翻译(NMT)作为最先进的神经网络技术基准而提及。
神经机器翻译研究产出
自2014年1月1日至2018年7月31日期间在Arxiv.org上发表的标题或摘要提及神经机器翻译(NMT)的研究论文
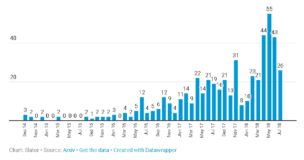
这对神经机器翻译(NMT)研究人员来说当然是个好兆头,但也意味着在搜索Arxiv数据库时会出现越来越多的误报。此外,随着研究人员更新他们的论文,以前发布版本的重新提交和更新的数量也在增加。
进化中的研究方向
假以时日,自神经机器翻译(NMT)成为主流以来,一般性的研究课题已经发生了变化。 2017年11月1日至2018年2月14日期间,Arxiv上的研究主要集中在这样几个议题上,即提高产出质量和解决训练数据限制(例如资源匮乏语言)。
看看那些参与了2018年2月15日到2018年4月底之间那些论文的公司,似乎那些主要参与者正在采取完全独立的研究方向,研究他们自己的课题。
例如,Facebook人工智能研究(FAIR)团队正忙于解决资源匮乏语言的问题,这也是Facebook的现实挑战,在2017年用户数达到了20亿后,每天的翻译需求达到了45亿次。
与此同时,亚马逊正在寻求更好的运营效率,对于他们面向云平台的企业用户以及语言服务提供商(LSP)的产品而言,这是说得通的。他们同样可以从改进的神经机器翻译(NMT)流程和速度中受益。
亚马逊研究的一篇论文是“约束解码”(constrained decoding),这种方法允许神经机器翻译(NMT)在翻译特定的单词或术语时保持一致性。问题在于,对于神经机器翻译(NMT)引擎需要记住每个单词并以特定的方式进行翻译,整个系统似乎慢了一些。
另一方面,谷歌似乎也专注于提高神经机器翻译(NMT)的产出,尽管这个搜索巨头像往常一样盯着几乎整个馅饼。 谷歌大脑(Google Brain)的研究人员与微软就资源匮乏语言、机器阅读和问答以及无监督学习共同撰写了论文。
谷歌甚至提出了改进的模型,这些模型基本上是现有神经机器翻译(NMT)引擎的混合体。据谷歌称,这些混合体的表现是最先进的,包括他们自己的谷歌翻译转换模型。
仍在崛起,并且已经影响到相关产业
神经机器翻译(NMT)仍在兴起,由学术界牵头并由企业方提供帮助的研究,正在大跨步前进。实际上,2018年上半年已经见证了研究界的活跃程度,2018年4月后的5月被视为神经机器翻译(NMT)最繁荣的月份。
神经机器翻译(NMT)的竞争同样蔓延到了开源。 Systran的全球首席技术官Jean Sellenart在2018年SlatorCon London期间评论说:
“过去两年中,每个月便大约有两个新的NMT开源项目。”
甚至出现了一种雪球效应。该技术提供了如此的广度和深度,即便是竞争公司有时也会一起研究共同的课题。 “世界上没有哪个公司可以复制250篇论文,只是为了检查它们是对还是错,”Senellart说道, “这也是今天开源必不可少的原因之一。”
越来越多的熟悉名字
在2018年5月、6月和7月,更多熟悉的名字进入Arxiv的研究论文。谷歌,微软和亚马逊等这种常规选手当然也在,以及语言行业的Systran,Ubiqus和SDL。
电子商务巨头阿里巴巴和互联网公司腾讯均发表了论文,这很好地代表了中国——甚至搜狗也发表了一篇论文,尽管并不是专门针对神经机器翻译(NMT)的。
最近,就在2018年7月,腾讯采用实验方法检测神经机器翻译(NMT)中的问题且不依赖于参考翻译并直接进行了投产。 BLEU(双语评估替代)指标使用类似的参考译文来评估机器翻译(MT)的输出,但由于不适合NMT而受到了批评。
“我们的实验结果表明,新方法可以在真实世界的数据集上实现高效率,”腾讯的论文摘要写道,“我们在有超过10亿月活跃用户的通信应用WeChat的开发和生产环境中部署提议算法的成功经验,有助于消除我们神经机器翻译(NMT)模型的众多缺陷,监控实际翻译任务的有效性,并收集内部测试案例,产生了高度的行业影响。”
通过研究提高准确性和充分性,提高运营效率和文件层面的上下文语境,加快了NMT产出的竞争。资源匮乏语言也成为众多研究人员和日本团队(较突出的NICT和NAIST)以及中国加快步伐的优先事项。
在商业世界中,整个供应链正在迅速感受着更高质量的机器翻译的影响,并且已经影响到了单位价格预期。有关神经机器翻译当前最新技术的专家分析和见解,请购买Slator的神经机器翻译2018年度报告。
翻译:Nansey 来源: Slator
评论
发表评论